데이터 전처리 – 자주 사용하는 전처리 (금융데이터)
데이터 준비
https://finance.naver.com/item/main.nhn?code=005930
import pandas as pd
import io
csv_text = '''
시가총액,336조 988 억원
시가총액순위,코스피 1위
상장주식수,5969782550
액면가l매매단위,100원 l 1주
'''
df = pd.read_csv(io.StringIO(csv_text), header=None)
df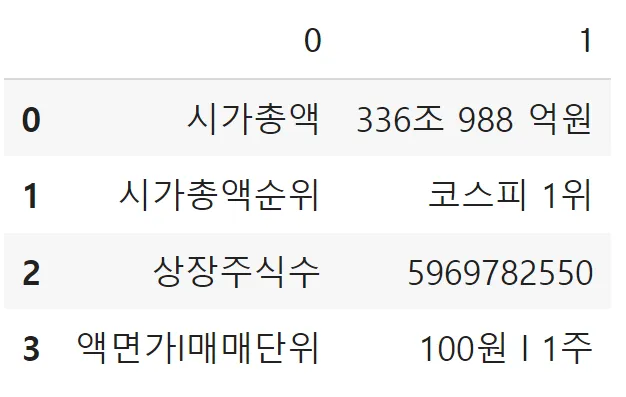
# 시가총액, 시가총액순위, 상장주식수
시가총액 = df.iloc[0, 1]
시가총액순위 = df.iloc[1, 1]
상장주식수 = df.iloc[2, 1]
# 액면가l매매단위
s = df.iloc[3, 1]
액면가 = s.split('l')[0].strip()
매매단위 = s.split('l')[1].strip()
시가총액, 시가총액순위, 상장주식수, 액면가, 매매단위
#결과 : ('336조 988 억원', '코스피 1위', '5969782550', '100원', '1주')문자열 다루기
1) 데이터 분리 – str.split() 활용하기
s = '시가총액 시가총액순위 상장주식수 액면가 매매단위'
s.split()
#공백을 기준으로 분리 후 리스트로 데이터를 저장해줌
#결과 : ['시가총액', '시가총액순위', '상장주식수', '액면가', '매매단위']s = ' 시가총액, 시가총액순위, 상장주식수 , 액면가, 매매단위'
s.split(',') # 단어 앞뒤에 공백문자
#결과 : [' 시가총액', ' 시가총액순위', ' 상장주식수 ', ' 액면가', ' 매매단위']s = '시가총액, 시가총액순위, 상장주식수, 액면가, 매매단위'
[x.strip() for x in s.split(',')] # 단어 앞뒤에 공백문자 제거
#결과 : ['시가총액', '시가총액순위', '상장주식수', '액면가', '매매단위']2) str.split(), str.join()
- list = str.split(‘구분자’): 구분자를 기준으로 나누기(split)
- ‘구분자’.join(list): 구분자를 넣어서 결합(join)
s = "화학|출판|전기제품|제약|은행"splited = s.split('|')
splited
#결과 : ['화학', '출판', '전기제품', '제약', '은행']r = ','.join(splited)
r
#결과 : 화학,출판,전기제품,제약,은행','.join(s.split('|')) #막대를 기준으로 데이터를 쪼갠 후, 콤마로 데이터를 변경해줌
#결과 : 화학,출판,전기제품,제약,은행3) n번째 가져오기
s = "화학 | 출판 | 전기제품 | 제약 | 은행"
s.split('|')
#결과 : ['화학 ', ' 출판 ', ' 전기제품 ', ' 제약 ', ' 은행']s.split('|')[1].strip() # 두번째
#결과 : 출판4) 불필요한 문자는 제거하고 수치값을 만들기
s1 = '8,832,934원'
s2 = '6,331원'
s1.replace(',', '').replace('원', '')
#결과 : ‘8832934’p1 = int(s1.replace(',', '').replace('원', ''))
p1
#결과 : 8832934# 함수로 만들기
def str_to_num(s):
return int(s.replace(',', '').replace('원', ''))
s1 = '8,832,934원'
s2 = '6,331원'
str_to_num(s1) + str_to_num(s2)
#결과 : 8839265# 결합한 예제
s = ‘96,800 | 42,300 | 104,875’
[int(x.replace(‘,’,”)) for x in s.split(‘|’)]
#결과 : [96800, 42300, 104875]
숫자만 추출하기
1) 문자열에서 숫자만 추출하기
text = '합계 4,456.3원 '
list(text)
#결과 : ['합', '계', ' ', ' ', '4', ',', '4', '5', '6', '.', '3', '원', ' ']# 숫자와 '.', '-' 만 남기기
num = ''.join([ch for ch in list(text) if ch in '-.0123456789'])
# float로 변환하기
float(num)
#결과 : 4456.32) 유틸리티 함수 만들기
파이썬 함수를 계속 사용하기 보다 일반화해서 함수로 정리해서 사용하는 것을 추천 합니다. (정규식을 사용하면 더 간단하고 빠르게 동작하는 함수를 만들 수 있습니다)
def str_to_num(s):
try:
s = str(s) # 문자열로 변환(soup 객체 경우 대응)
num = ''.join([ch for ch in list(s) if ch in '-.0123456789'])
return float(num) if '.' in num else int(num)
except:
print(f'Cannot convert "{s}" to number')
pass
return Nonestr_to_num('합계 4,456.3원 ') # 4456.3
str_to_num('$3,344,021.3 ') # 3344021.3
str_to_num('합계: 3,344 ') # 3344
str_to_num('텍스트만 있는 경우') # Cannot convert "텍스트만 있는 경우" to number문자열과 날짜
pd.to_datetime() 문자열을 날짜로 (str to Datetimeindex)
import pandas as pd
data = [
['2021-09-10', 30],
['2021-09-15', 40],
]
df = pd.DataFrame(data, columns=['TIME', 'VALUE'])
dfdf['TIME'] = pd.to_datetime(df['TIME'])
df월 문자열 데이터
data = [
['202101', 10],
['202102', 30],
['202103', 25],
['202104', 40],
]
df = pd.DataFrame(data, columns=['DATE', 'VALUE'])
df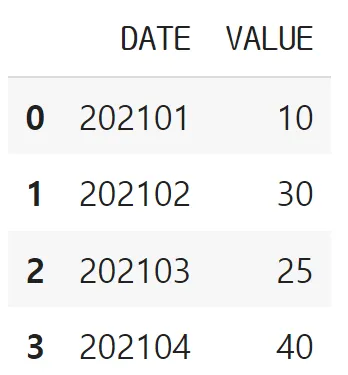
pd.to_datetime(df['DATE'], format="%Y%m")
#결과
0 2021-01-01
1 2021-02-01
2 2021-03-01
3 2021-04-01
Name: DATE, dtype: datetime64[ns]실습 노트북
2018-2024 FinanceData.KR
출처 : https://financedata.notion.site/3091ea79cbcd49ef93e3499929327a79