데이터 전처리
- 데이터 분석에 적합하게 데이터를 가공하는 작업
- 전처리가 분석 결과에 직접적인 영향
- 데이터 분석의 단계 중 가장 많은 시간이 소요
- 데이터 정제 → 결측값 처리 → 이상값 처리 → 분석변수 처리 (일반적으로)
가장 비용이 많이 소요되는 작업
Data preparation: 80% of the work of data scientists

forbes.com https://goo.gl/h2DtR5
“데이터 과학의 80%는 데이터 클리닝에 소비되고, 나머지 20%는 데이터 클리닝하는 시간을 불평하는데 쓰인다.” — kaggle 창립자 Anthony Goldbloom
데이터셋 (Dataset)
| 표 (table) | 데이터셋(dataset), 인스턴스 집합(set of instance) |
|---|---|
| 행 (row) | 관측치(observed value), 레코드(record), 샘플(sample), 개체(instance) |
| 열 (column) | 특성(feature), 속성(attribute), 변수(variable) |
참고 (머신러닝 에서, 통계에서)
| 독립변수 | X | feature | 입력 | |
|---|---|---|---|---|
| 종속변수 | y | target | 출력 | 레이블, 정답 |
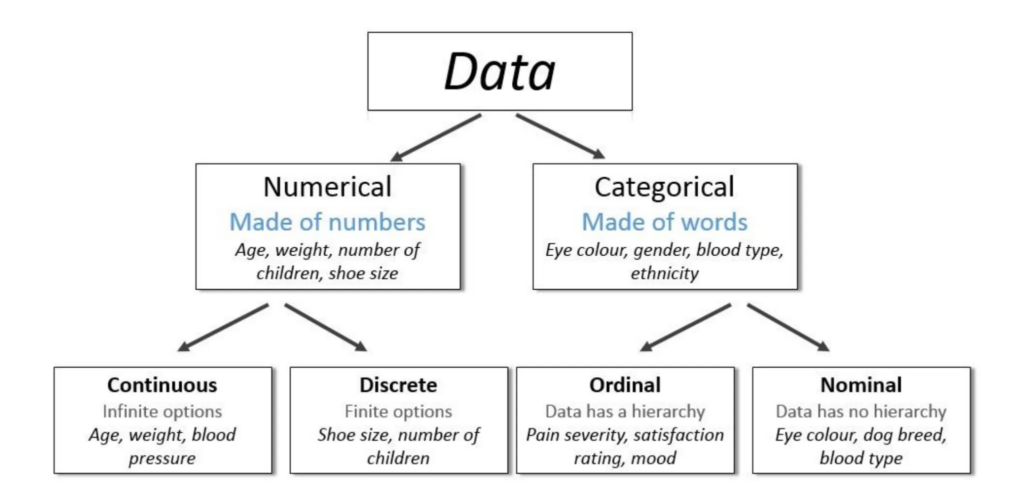
데이터 분류 (Data Classification)
양적 데이터 (정량적, Quantitative or Numeric)
- 연속 (continuous) : 예) 키, 몸무게, 온도 (실수로 표현)
- 이산 (discrete) : 예) 몇개의 값, 회수, 가족수 (정수로 표현)
질적 데이터 (정성적, Qualitative or Categorical)
- 범주(명목형, nominal) 순서가 없는 예) 인종, 성별, 지역
- 순서(서수형, ordinal) 순서가 있는 예) 등급, 순위
https://i.imgur.com/tZWaltL.png
{kind=link}
척도 (scale)
관찰된 결과에 특정 값을 할당하기 위해 사용되는 측정 수준
| 명목척도 nominal scale | 어떤 범주에 속하는가 | 순서나 크기의 의미 없음 | 종교, 인종, 성별, 지지정당 |
| 서열척도 ordinal scale | 순위 부여 | 등간격 아님, 연산 불가 크기나 순서 간의 차이X | 5점 척도 만족도 |
| 구간척도 interval scale | 명목, 순서 척도 + 등간격 | 크기비교 의미 있음 크기간의 차이 동일 | 온도, 물가지수, 주가지수 |
| 비율척도 ratio scale | 구간척도의 특성 + 절대 원점 | 크기비교와 비율도 의미 0을 기준 크기 표시가능 | 키, 몸무게, 시간, 거리 |
- 순서척도는 범주형 데이터
- 정보의 양 : 명목척도 < 순서척도 < 구간척도 < 비율척도
데이터 전처리 (Data preprocessing)
- 원시 데이터(raw data)를 정제 데이터(clean data)로 만드는 작업
- 데이터를 분석 및 처리에 적합한 형태로 만드는 과정을 총칭
- 데이터 분석, 데이터 마이닝, 머신러닝 모두에 항상 필요
- 좋지 않은 데이터로 좋은 결과를 얻을 수 없음
데이터 전처리가 필요한 이유
- 잡음 (noise): 측정 과정에서 무작위로 발생 (에러)
- 이상치 (outlier): 대부분의 데이터와 지나치게 다른 특성 혹은 다른 범위 (잡음과 다르다)
- 부적합 (inconsistent): 모순, 불일치 데이터 (예: 동일한 우편번호에 지역 주소)
- 결측치 (missing value): 누락된 데이터 혹은 속성
- 중복 (duplicated): 동일한 데이터
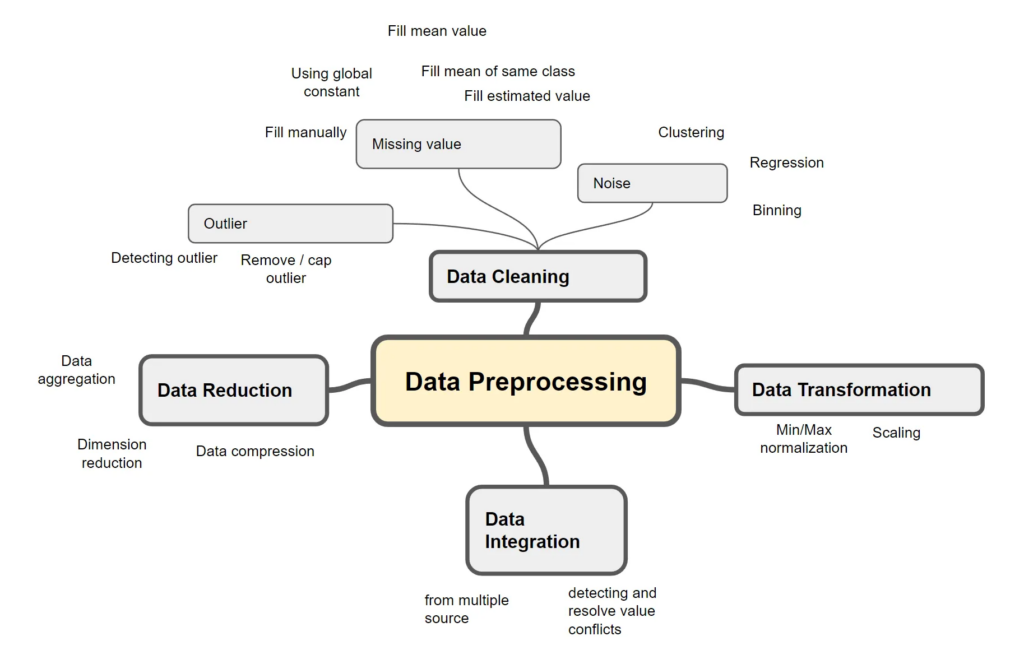
데이터 전처리 작업
- 데이터 정제(Data Cleaning)
- 수집된 데이터에서 오류, 누락값, 이상치 등을 식별하고 처리하는 과정
- 중복 데이터 제거, 누락값 처리, 이상치 처리
- 잡음 제거, 부적합 제거, 읽을 수 없는 요소 제거
- 형식(수치값, 날짜) 일관성 유지
- 데이터 통합(Data Integration)
- 여러 소스에서 수집된 데이터를 하나의 일관된 형식으로 통합하는 과정
- 데이터 형식 통일, 데이터 스키마 매핑, 데이터 병합
- 다양한 소스에서 얻은 데이터를 동일한 단위나 단일 형식으로 변경
- 이름 의미 일관성 유지 (명칭을 동일하게), 메타 데이터 유지 관리
- 데이터 변환(Data Transformation)
- 데이터를 분석에 적합한 형태로 변환하는 과정
- 데이터 정규화, 스케일링, 인코딩, 파생 변수 생성 등
- 데이터 축소(Data Reduction)
- 데이터의 크기를 줄이면서 핵심 정보는 유지하는 과정
- 차원 축소(PCA, t-SNE 등), 샘플링, 특성 선택, 이산화 등
- 데이터 분할 (Data Splitting)
- 데이터를 훈련 데이터, 검증 데이터, 테스트 데이터로 분할하는 과정
- 머신러닝 모델 학습 및 평가를 위해 데이터를 적절히 분할
- 데이터 검증 (Data Validation)
- 전처리된 데이터의 품질과 일관성을 검증하는 과정
- 데이터 타입 검사, 제약 조건 확인, 통계적 분석 등


출처1: bdataanalytics.biomedcentral.com, 출처2: bdataanalytics.biomedcentral.com
데이터 전처리 기법
데이터 정제 – 결측값 (Missing Value)
결측값: 값이 존재하지않고 비어있는 상태
- NA (Not Available), NaN (Not a Number), NULL
- 결측치의 비중이 높으면 데이터가 불충분
결측값의 성격
- 완전히 랜덤하게 발생 (거의 없음)
- 조건에 따라(다른 변수의 영향) 랜덤하게 발생
- 랜덤하지 않음 (누락된 이유가 존재)
결측값 처리 방법
결측값을 잘 채워넣는 것이 매우 중요함
- 결측값 무시하고 분석
- 다시 조사하여 데이터를 수집 보강
- 결측값을 포함한 데이터 개체(row) 또는 속성(column) 제거
- 특정 상수로 채우기 (예, 0으로 채우기)
- 결측값 추정하여 채워넣기 (최근에는 평균값보다 중간값(Median)을 채우는 것이 더 적정한 결과를 보임)
결측값 추정
- 속성(column)의 대푯값(평균값, 중앙값 등)을 사용하여 채우기
- 동일한 속성값의 평균값 (혹은 중앙값) 사용
- 결측값을 예측 (회귀 분석, 베이지안 추론, 의사결정나무 등)
데이터 정제 – 잡음 (Noise)
데이터 평활화 기법(smoothing technique)
- 구간화 (Binning): 정렬된 데이터를 빈(혹은버킷)으로 분할
- 회귀 (Regression): 회귀 분석을 통해 평활화
- 군집화 (Clustering): 유사한 값들이 그룹화 (outlier: 특정 군집에 속하지 않은 값)

https://en.wikipedia.org/wiki/DBSCAN
이상치 (Outliers) 탐지와 처리
이상치 탐지
- 표준편차 3 이상
- IQR
이상치 처리
- 값을 제거
- 값을 특정 범위로 제한
요약
2018-2025 FinanceData.KR
데이터 전처리는 데이터 분석 시 가장 중요하고 시간이 오래 걸리는 작업입니다.
본 내용은 본인이 이승준 교수님(한국금융연수원 겸임교수이자 FinanceData.KR 대표)의 수업을 들으며 정리한 내용입니다.
출처 : FinanceData.KR (https://financedata.notion.site/54690591e5e24213b1b32d6b98bb6c70)