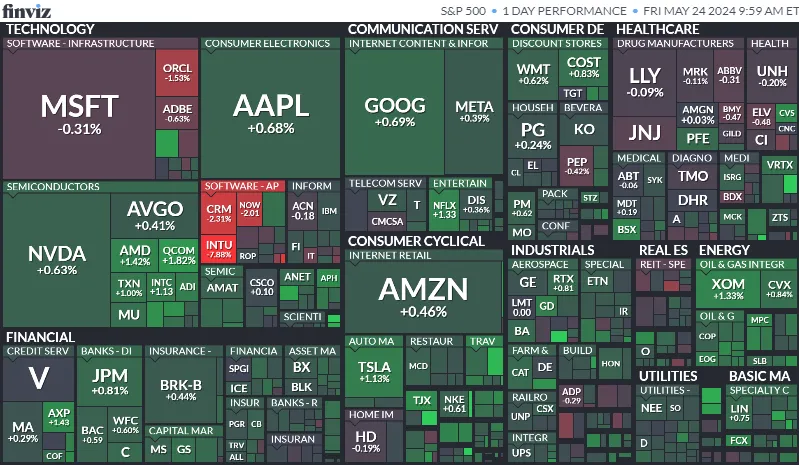
셀레니움을 활용하여 finviz사이트의 S&P 500 Treemap을 가져오는 크롤링하는 방법을 알려드리겠습니다.
혹시 셀레니움이 뭔지 모르신다면 이전 포스팅을 먼저 읽어보고 오시는것을 추천드립니다.
셀레니움 포스팅 ☞ 바로가기
Anaconda 설치 후 주피터 노트북에서 실습하거나 Colab에서 실습해보실 수 있습니다.
finviz S&P 500 Treemap 데이터 크롤링 하기
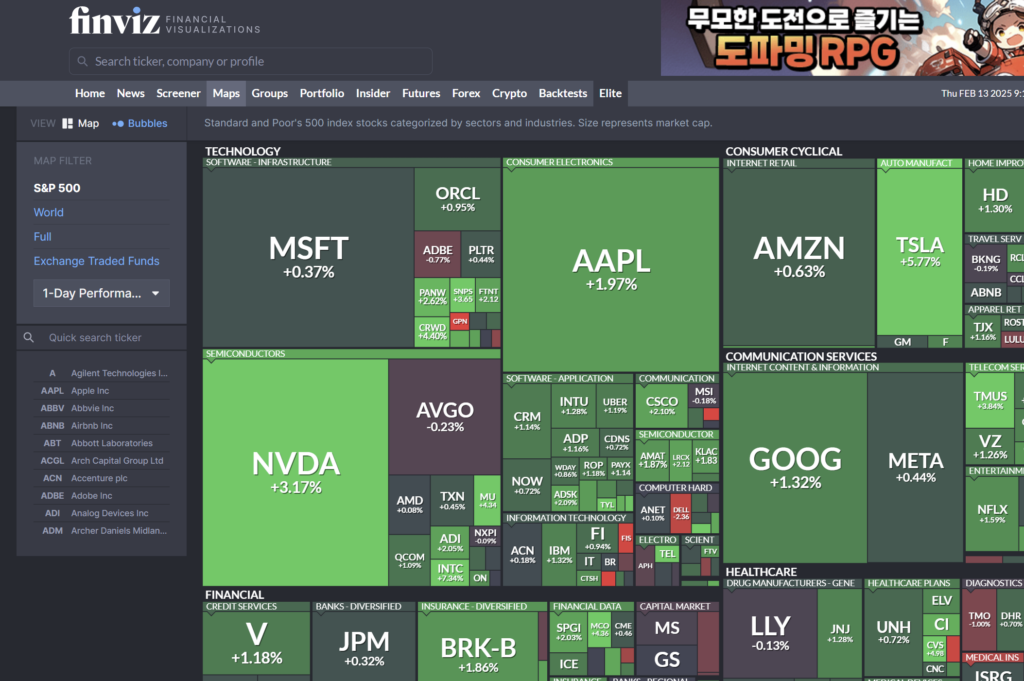
finbiz사이트는 유명한 미국 주식에 대한 실시간 정보를 편리하게 확인할 수 있습니다.
그중 Maps 탭에서 “Share Map”버튼을 누르면 생성되는 이미지를 크롤링 해오는 실습을 한번 해보겠습니다. 이 주소는 “Share Map”버튼을 누를 때 마다 생성이 되기 때문에, 기존의 크롤링 방법으로는 데이터를 가져오기 어렵고 셀레니엄과같은 브라우저 자동화 툴을 이용해 가져올 수 있습니다.
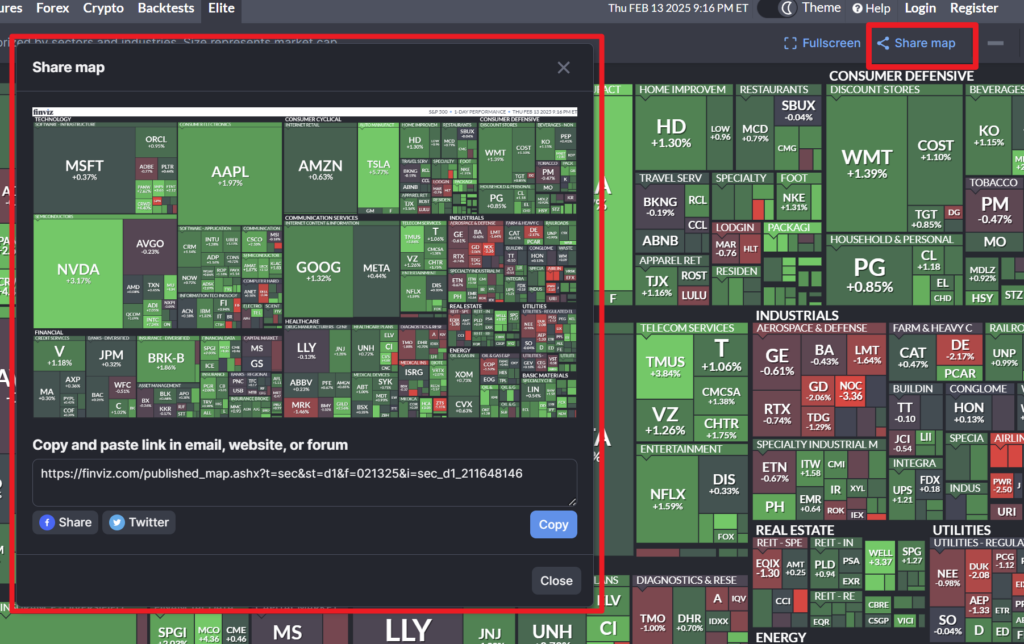
1) 셀레니움 드라이버 실행
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
service=Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver2) 페이지 방문, 요소 클릭(click)
driver.get('<https://finviz.com/map.ashx>')
from selenium.webdriver.common.by import By
button = driver.find_element(By.XPATH, "//div[contains(text(), 'Share map')]")
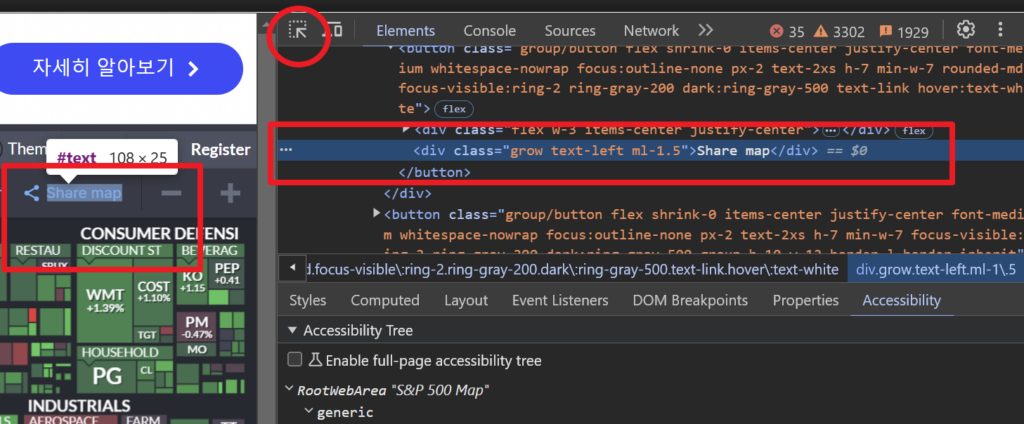
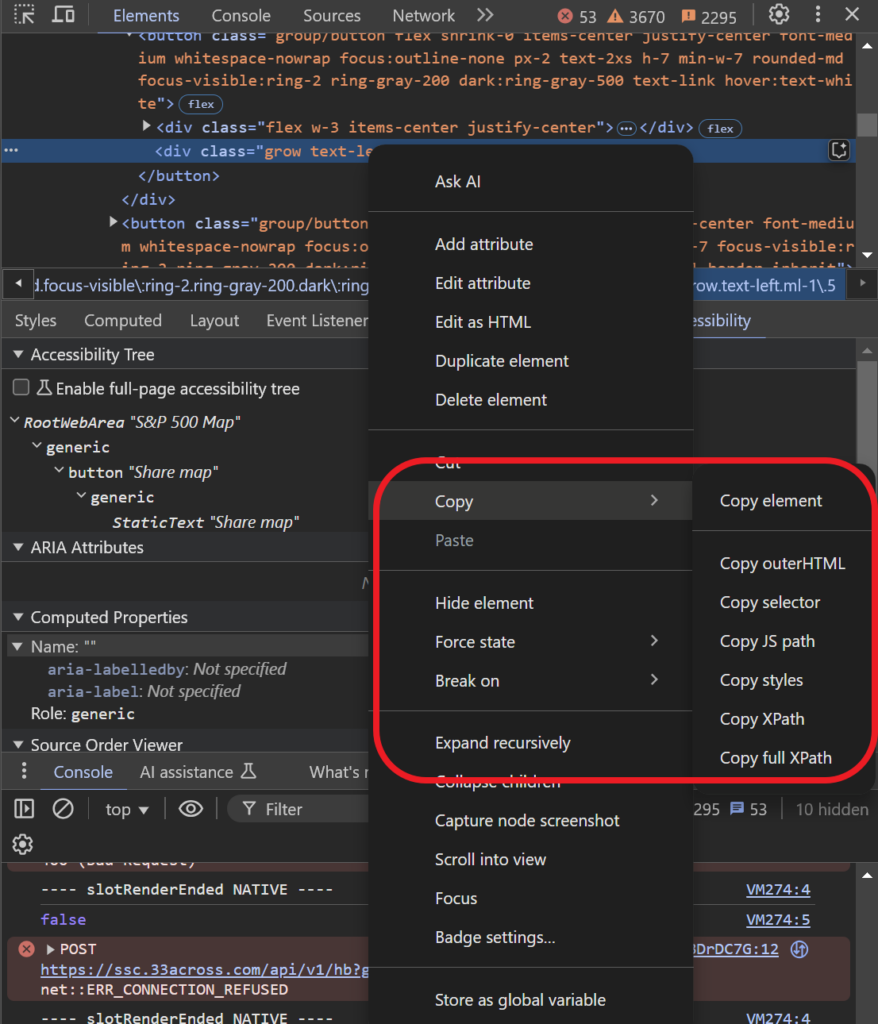
button.click()참고로, 해당 버튼에 대한 XPATH 정보는 크롬의 개발자도구 (F12키 누르면 나옴)에서 아래 빨간색 동그라미 버튼을 누른 후, 브라우저에서 “Share map”컴포넌트를 클릭하면 해당 컴포넌트에 대한 html스크립트를 확인할 수 있고, 해당 스크립트에서 COPY > XPath를 따로 복사할 수 있습니다.
어떤 사이트든 동일한 방법으로 XPath를 가져올 수 있습니다.
3) 페이지 소스에서 이미지 URL 가져오기
from bs4 import BeautifulSoup
soup = BeautifulSoup(driver.page_source, features='html5lib')
img = soup.find('img', {'alt':'S&P 500 Map'})
treemap_url = img['src']
treemap_url 4) 이미지 URL을 읽어 이미지로 저장
import requests
r = requests.get(treemap_url, headers={'User-Agent':'Mozilla/5.0'})
with open('finviz_map.png', 'wb') as f:
f.write(r.content)
전체 코드
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# 1) webdriver 실행 (headless)
service=Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
# 2) 페이지 방문, 요소 클릭(click)
driver.get('<https://finviz.com/map.ashx>')
button = driver.find_element(By.XPATH, "//div[contains(text(), 'Share map')]")
button.click()
time.sleep(3)
# 3) 페이지 소스에서 이미지 URL 가져오기
soup = BeautifulSoup(driver.page_source, features='html5lib')
img = soup.find('img', {'alt':'S&P 500 Map'})
treemap_url = img['src']
# 4) 이미지 URL을 읽어 이미지로 저장
r = requests.get(treemap_url, headers={'User-Agent':'Mozilla/5.0'})
with open('finviz_map.png', 'wb') as f:
f.write(r.content)
driver.close()
from IPython.display import display
from PIL import Image
display(Image.open('finviz_map.png'))