데이터 준비
결측치 처리
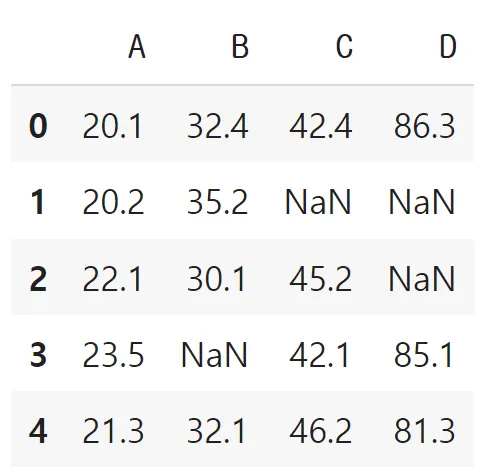
결측치 처리: 개수 확인
# 결측치 개수
df.isnull().sum()# 결측치 개수 (전체)
df.isnull().sum().sum()df.dropna() # df.dropna(axis=0)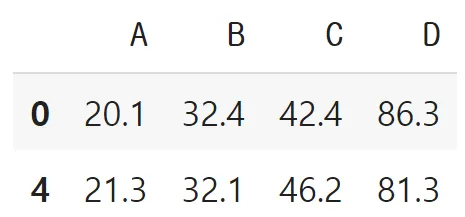
결측치 처리: 데이터 혹은 컬럼 삭제
- dropna()
- 간편하지만, 관측점 (혹은 변수)가 감소
df.dropna(axis=1)
df.dropna(axis=1, how='all') # 컬럼의 모든 값이 NaN 경우만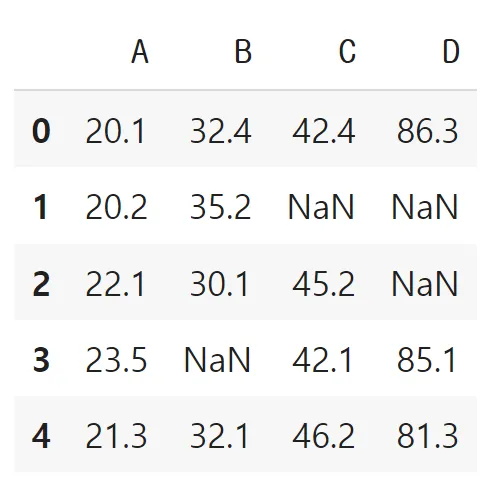
결측치 처리: 대체 (imputation)
df.median()# 결측치를 median으로 대체
df.fillna(df.median())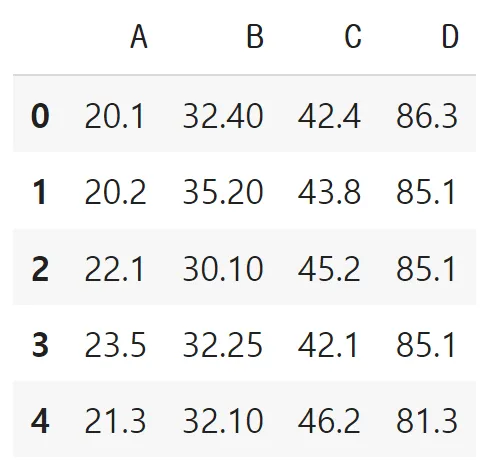
Outlier 탐지
- 표준편차 3 이상
- IQR
df = pd.DataFrame({'data': np.random.normal(size=500)})
df.head()
3표준편차 와 IQR 방법
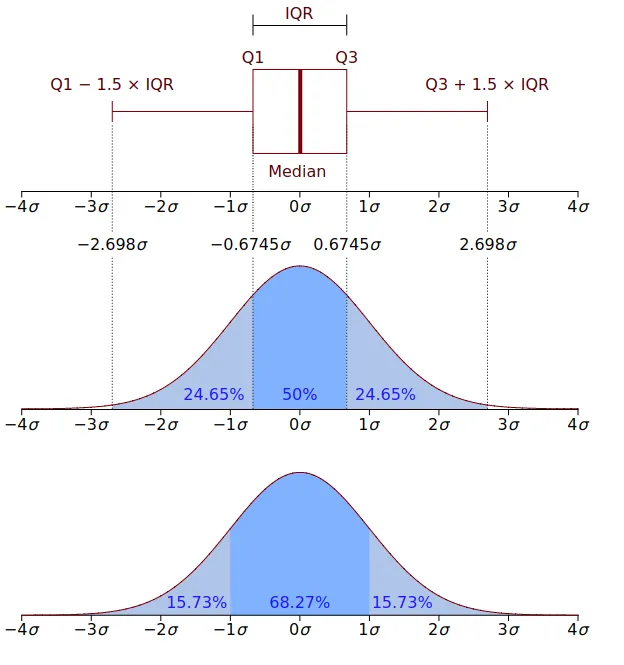
Outlier 처리: QR 이용하는 방법
# Outlier 탐지
outlier_conds = np.abs(df['data'] - df['data'].mean()) > (3*df['data'].std())
print('row count', len(df[outlier_conds]))Outlier 처리: IQR 이용하는 방법
df['data'].quantile([0.25, 0.75])q1, q3 = df['data'].quantile([0.25, 0.75])
IQR = q3 - q1
lower_bound = q1 - (IQR * 1.5)
upper_bound = q3 + (IQR * 1.5)
out_conds = (df['data'] < lower_bound) | (upper_bound < df['data'])
df[out_conds]잡음값 처리
데이터 평활화
- 비닝(Binning)
- 회귀(Regression)
- 군집화 (Clustering)
잡음값 처리: 비닝
- 연속형 변수를 범주형 변수로
- 몇 개의 BIN (혹은 버킷)으로 분할
data = np.random.randint(1, 10, 7)
datapd.cut(data, 3)pd.cut(data, 3, labels=['별로', '보통', '좋음'])데이터 변환 (Data Transformation)
정규화(Normalization) vs 표준화(Standardization)
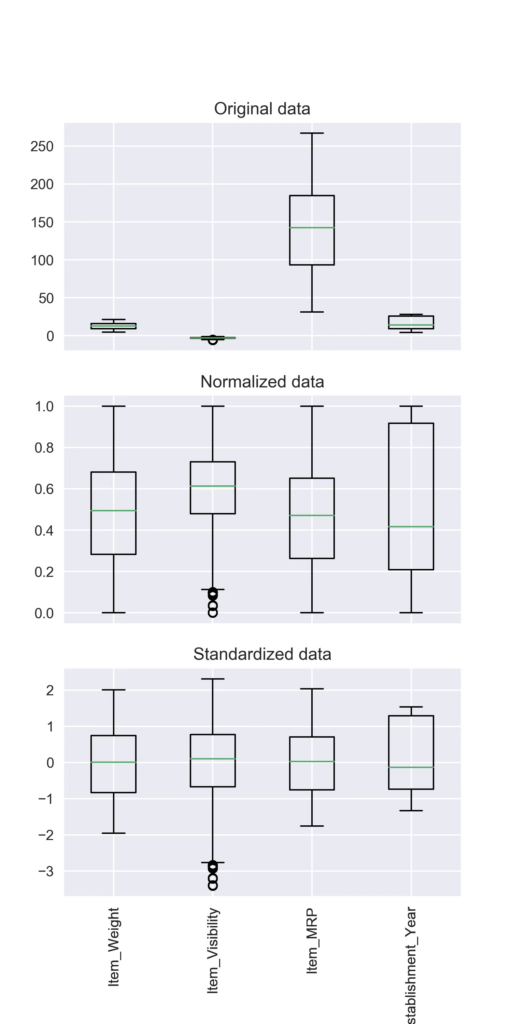
- 단위를 무시하고, 차이는 유지하여 비교 가능하도록 데이터를 변환
- 정규화: 같은 범위, 표준화: 같은 통계량
- 효과
- 머신러닝에서 scale이 큰 feature의 영향력이 커지는 것을 방지
- 딥러닝에서 local minima 위험↓ (학습속도↑)
정규화 (Normalization)
- 공통 범위가 되도록 변환 (차이는 유지)
- 피처의 범위가 크게 다른 경우
- MinMaxScaler (0~1), Normalizer (방향 유지 + 크기 1 단위 벡터로)
표준화 (Standardization)
- 동일한 통계량(평균, 분산)이 되도록 변환
- Z-score 표준점수
- StandardScaler, RobustScaler
우측 그림 설명 : 원본데이터를 0~1까지의 크기로 맞춘것이 정규화, 0기준으로 값을 맞추면 표준화라고 요약 가능
데이터 스케일링
데이터에 선형 변환을 적용 자료의 분포를 균일하게 만드는 과정
- scale(X): 기본 스케일, 평균이 0, 분산을 1으로 선형변환
- robust_scale(X): 중앙값(median)0, IQR=1이 되도록 변환 (아웃라이어의 영향 최소화)
- minmax_scale(X): 최대값과 최소값이 각각 1, 0이 되도록 스케일링
- maxabs_scale(X): 최대절대값과 0이 각각 1, 0이 되도록 스케일링
import numpy as np
from sklearn.preprocessing import scale, robust_scale, minmax_scale, maxabs_scale
df = pd.DataFrame({'x':np.arange(-3, 9, dtype=float) })
df.iloc[-1] = 50 # outlier
df['scale(x)'] = scale(df[['x']])
df['robust_scale(x)'] = robust_scale(df[['x']])
df['minmax_scale(x)'] = minmax_scale(df[['x']])
df['maxabs_scale(x)'] = maxabs_scale(df[['x']])
df
df.describe()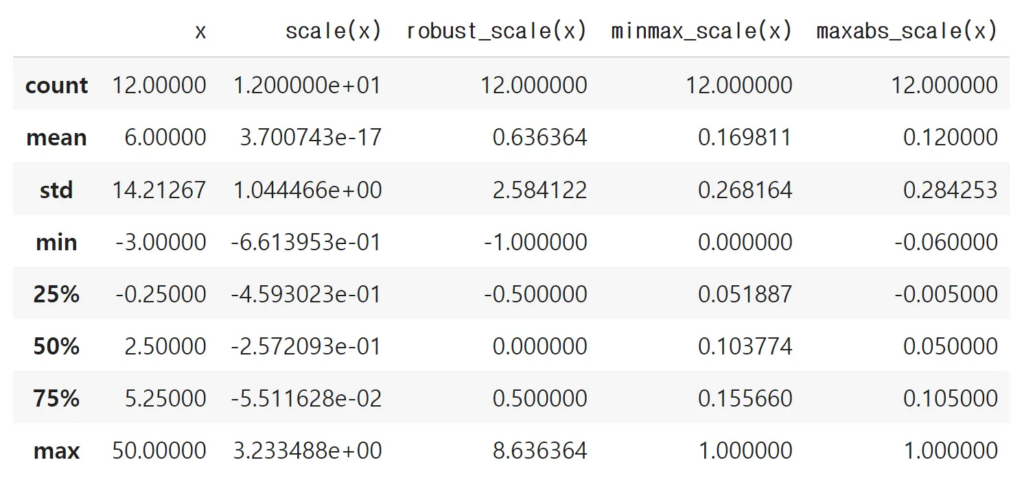
df.median() # robust_scale(x) == 0출처 : https://financedata.notion.site/e3f7ea28d66e40638e33307ecc6a3dd0