웹 크롤링이란?
자동화된 방법으로 웹을 탐색하고 데이터를 수집하는 작업
크롬 개발자 도구 (Chrome Developer Tools)
크롬에 기본 탑재된 웹 개발 및 디버깅 도구
- 우측 상단의 메뉴 > 도구 더 보기 > 개발자 도구 (F12)
- 요소(Elements), 네트워크(Network), 타임라인(Timeline) 등 기능
- 요소(Element) 탭: 웹 페이지 요소의 CSS와 HTML 검사
파이썬 라이브러리
requestsHTTP 요청/응답 처리 모듈BeautifulSoupPython library for pulling data out of HTML and XML file
크롤링 주요 이슈
- GET 요청:
requests.get() - POST 요청:
requests.post() - 응답 페이지 분석, 데이터 추출, 데이터 전처리
- 헤더 지정: requests 에 헤더값 지정
- 문자 인코딩 (
UTF-8,EUC-KR) - 로그인(인증): requests의 Session 객체 사용
- IP-Ban: 프록시 서버, 프록시 경유하기
- 동적으로 화면 혹은 데이터가 생성: Selenium 사용
크롬 개발자 도구
(Chrome Developer Tools) 크롬 브라우저에 기본 탑재된 웹 개발 및 디버깅 도구
- 실행: 메뉴 > 도구 더 보기 > 개발자 도구 (혹은 F12)
크롬 개발자 도구 – 요소(Element)
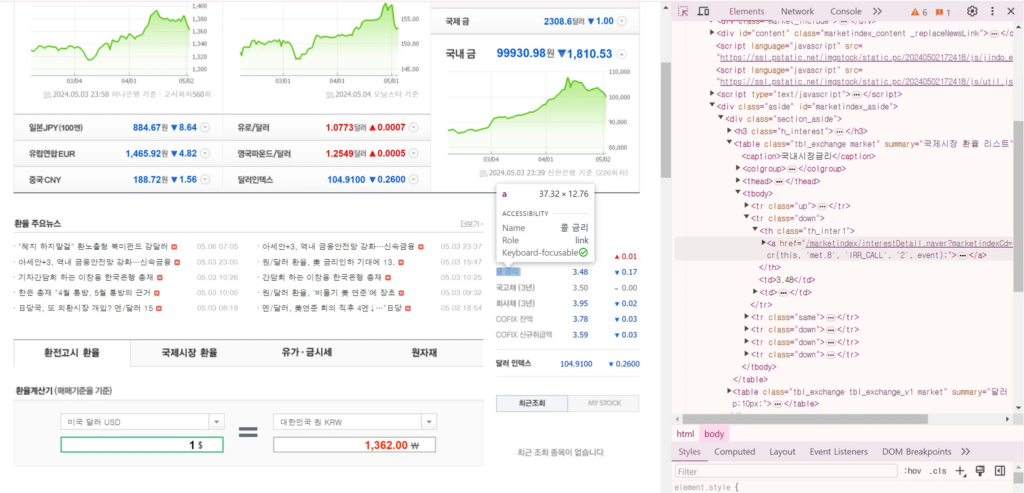
요소(Element): 웹 페이지 구성 요소 살펴보는 기능
- HTML 태그: table, tr, td, div, a href
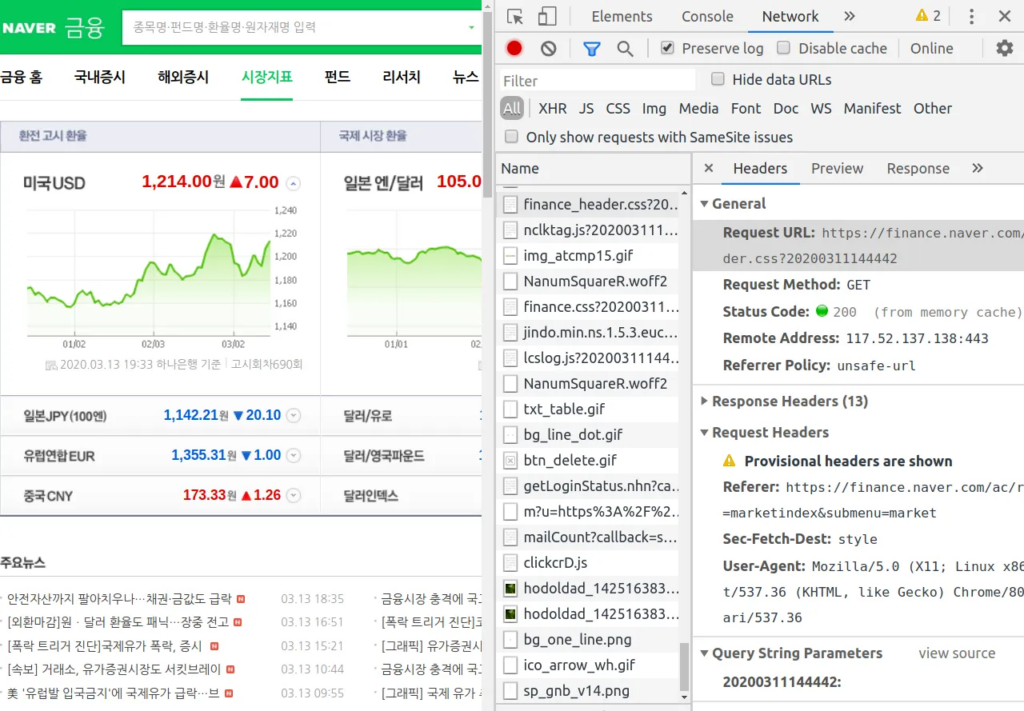
크롬 개발자 도구 – 네트워크(Network)
네트워크(Network): 브라우저와 서버 사이의 요청과 응답 살펴보는 기능
- XHR (XMLHttpRequest, =Ajax),JS, CSS, Img, Doc
- HTTP 헤더
- Request URL (요청 URL)
- Request Method (요청 메소드)
- Status Code (상태코드)
- Cookie (쿠키)
- User-Agent (사용자 에이전트)
- Referer (리퍼러)
웹 페이지 분석하기 – 요소(Element)
트래픽 분석하기 – 네트워크(Network)
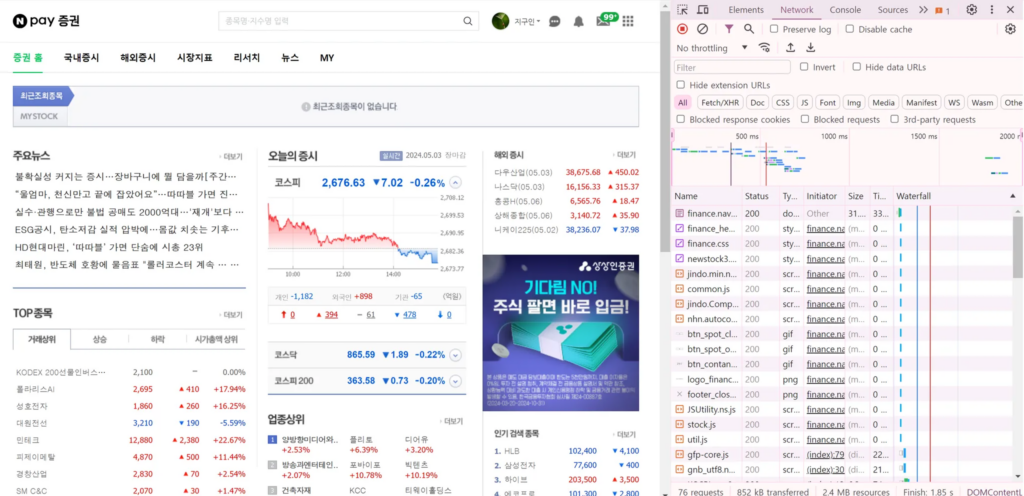
웹 네트워크 분석하기
- 웹이 동작하는 기본 원리
- HTTP 의 요청과 응답
- GET/POST 명령의 차이
- 크롬 개발자도구로 웹 네트워크 트래픽을 분석
실습 1) 크롬 개발자도구 소개
- 메뉴: 설정 / 도구 더 보기 / 개발자 도구
- 바로가기: F12 키
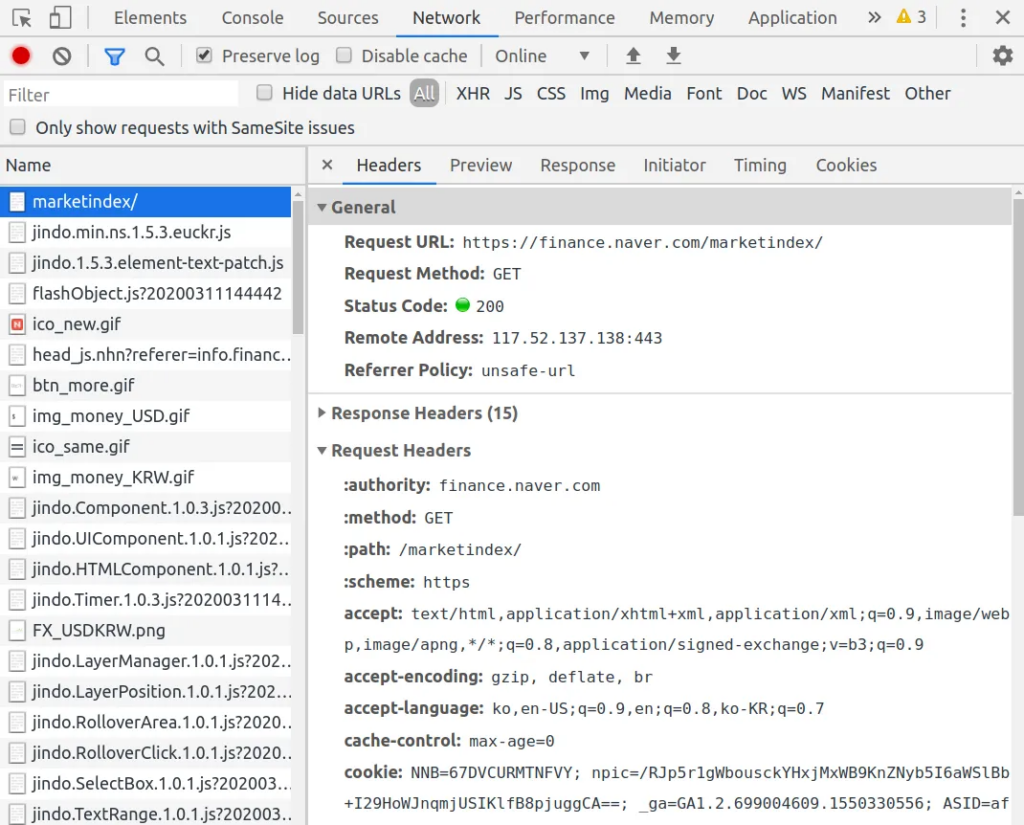
실습 2) 웹 페이지 분석하기 (크롬 개발자 도구)
- 메뉴: 설정 / 도구 더 보기 / 개발자 도구
- 바로가기: F12 키
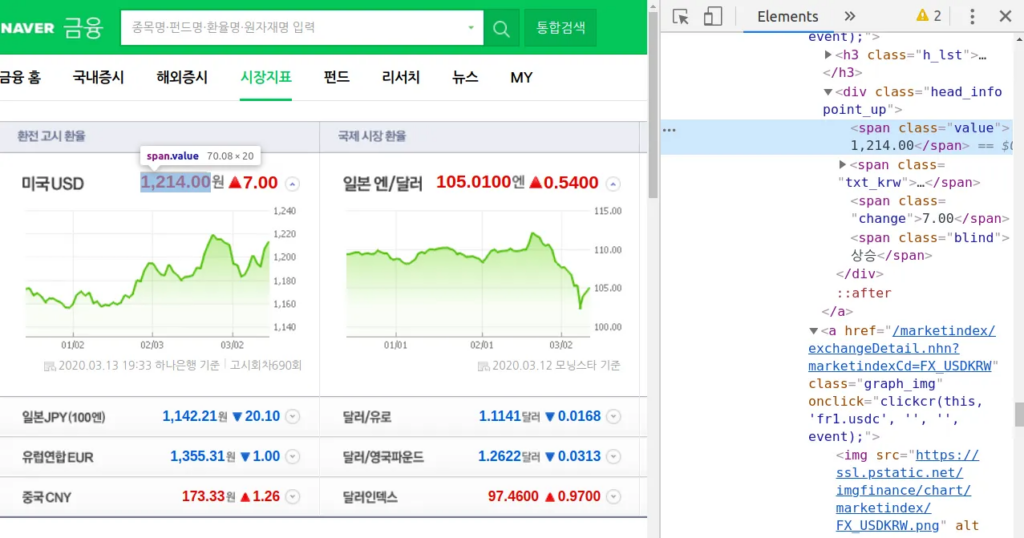
실습 3) 웹 네트워크 분석하기 (크롬 개발자 도구)
웹 크롤링 – requests, BeautifulSoup
간단한 요청 만들기
import requests
from bs4 import BeautifulSoup
url = "<https://www.google.com/search?q=삼성전자>"
r = requests.get(url)
soup = BeautifulSoup(r.text)
soup.title.text헤더 지정
headers = {
'user-agent': 'AppleWebKit Chrome/74',
'accept-language': 'ko'
}
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text)
a_list = soup.find_all('a')
for a in a_list:
print(a.text)네이버 파이낸스 기업현황
http://companyinfo.stock.naver.com/v1/company/c1010001.aspx?cmp_cd=005930
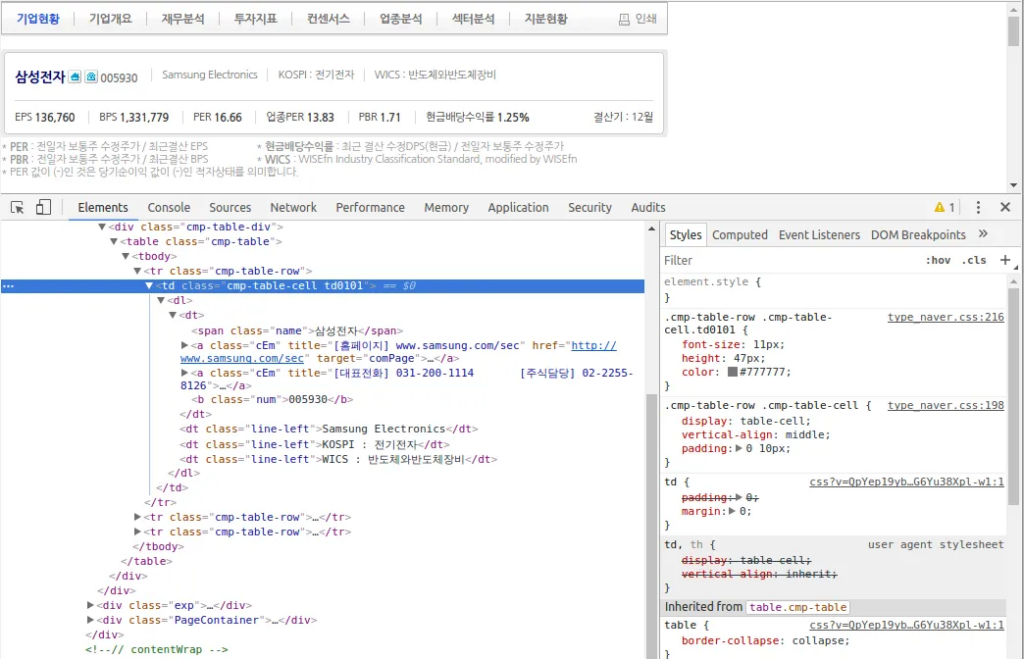
기업개요 요청과 응답
code = '005930'
url = '<http://companyinfo.stock.naver.com/v1/company/c1010001.aspx?cmp_cd=>' + code
r = requests.get(url)
soup = BeautifulSoup(r.text,"lxml")
td = soup.find('td', {'class':'cmp-table-cell td0101'})
td특정 요소 찾기 – find()
td.find('span', {'class':'name'}).text특정 요소 전체 찾기 – find_all()
anchors = td.find_all('a', {'class':'cEm'})
print(anchors[0]['href'])
print(anchors[1]['title'].replace('\\r', ''))특정 요소 전체 찾기 – find_all() 응용
dts = td.find_all('dt', {'class':'line-left'})
print(dts[0].text)
print(dts[1].text)
print(dts[2].text)실습 – 네이버 파이낸스 주요 지표 가져오기
https://finance.naver.com/marketindex/ (시장지표)
- 개발자 도구로 페이지 살펴보기
- 국내증시 주요지표 데이터 가져오기
- 해외시장 주요지표 데이터 가져오기
- pandas의 read_html() 로 간편하게 가져오기
- 엑셀로 저장하기