데이터 전처리 — 텍스트 데이터 인코딩
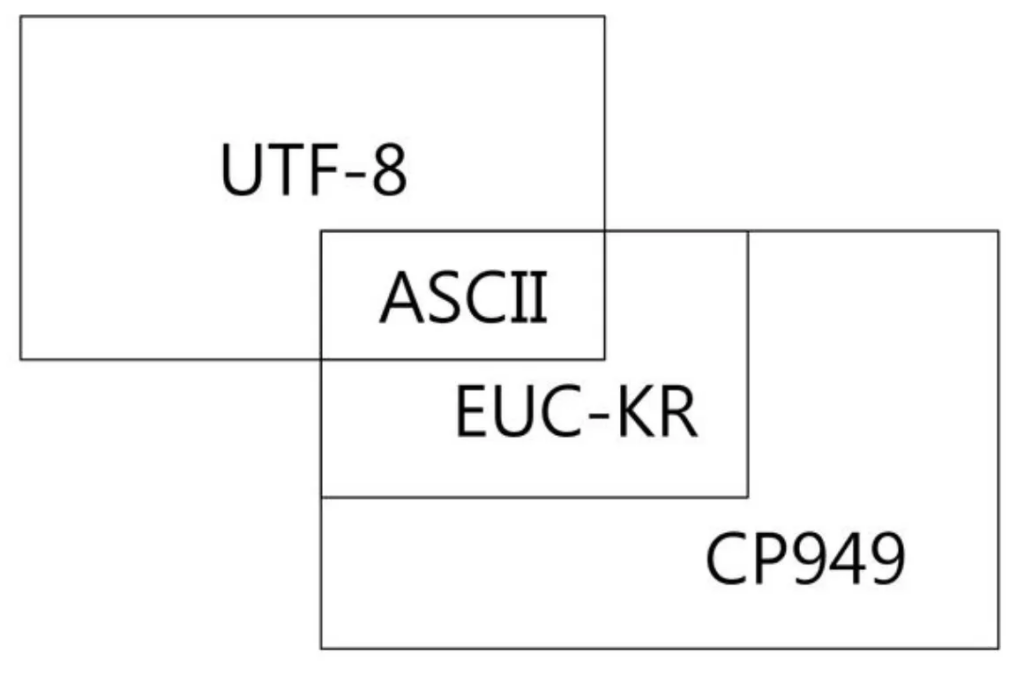
대표적인 인코딩
- ASCII
- EUC-KR
- CP949
- UTF-8
ASCII
- American Standard Code for Information Interchange
- 0x00 ~ 0x7F (7bit, 128개, 알파벳과 문장부호)
ISO 8859
- 0x00 ~ 0xFF (8bit, 256개, 알파벳과 다양한 기호와 문자)
- 언어권에 따라 변형 – 서유럽용 ISO 9959-1 (Latin-1)을 가장 많이 사용
UTF-8 : 유니코드
- Universal Coded Character Set + Transformation Format – 8-bit
- 유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나
- 가장 널리 사용되는 표준
EUC-KR
- EUC: Extend Unix Code
- 영어를 제외한 문자를 표현하기 위한 확장부호
- KS X 1001(KS C 5601 행망용)
- 대표적인 한글 완성형 인코딩
- 현대 한글 2,350자만 사용
CP949
- Code Page 949
- 마이크로소프트의 EUC-KR 확장 완성형 코드 (윈도 95부터 기본)
- 현대 한글 11,172자 표현
- 비표준 (국내에서 널리사용)
데이터 파일 다루기
open('master.csv') # 윈도우에서 기본: encoding='cp949'
open('master.csv') # 리눅스에서 기본: encoding='UTF-8'윈도우에서는 인코딩을 지정해주어야 합니다
lines = open('master.csv').readlines()
# UnicodeDecodeError: 'cp949' codec can't decode byte 0xec in position 138: illegal multibyte sequencelines = open('master.csv', encoding='utf-8').readlines()
lines[:10]인코딩 감지
import chardet
contents = open('master.csv', 'rb').read()
chardet.detect(contents)contents = open('rss_30100041.xml', 'rb').read()
chardet.detect(contents)인코딩 변환
# 읽기
contents = open('master.csv', 'r', encoding='utf-8').read()
# 쓰기
open('master-euckr.csv', 'w', encoding='euc-kr').write(contents)contents = open('master-euckr.csv', 'rb').read()
det = chardet.detect(contents)
det인코딩 일괄 변환
import glob
for fn in glob.glob('*.csv'):
contents = open(fn, 'rb').read()
det = chardet.detect(contents)
print(f"{fn} ({det['encoding']})")import glob
for fn in glob.glob('*.csv'):
# detect encoding
contents = open(fn, 'rb').read()
det = chardet.detect(contents)
# convert encoding
if str(det['encoding']).lower() == 'utf-8':
text = open('master.csv', 'r', encoding='utf-8').read()
open(fn.replace('.csv', '_euckr.csv'), 'w', encoding='euc-kr').write(text)참고
엑셀에서 utf-8 CSV 읽기
윈도우 엑셀은 csv의 기본 인코딩을 cp949(EUC-KR)로 가정
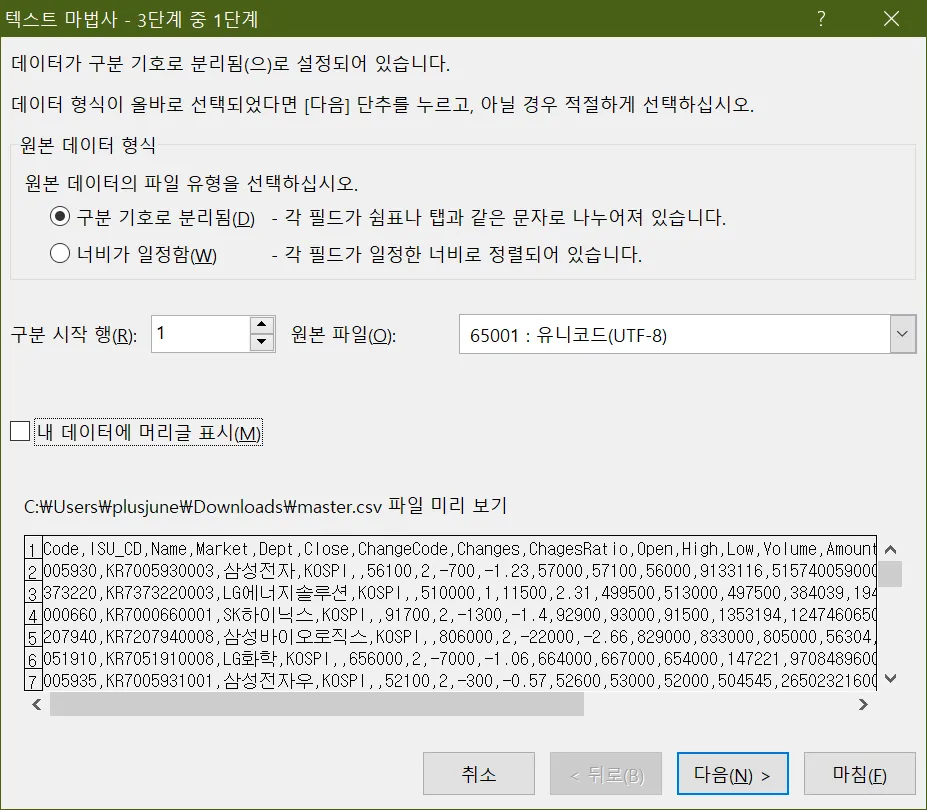
Codepage 변경
C:\\>chcp 949 # 확장 EUC-KR
C:\\>chcp 65001 # 유니코드 8bit요약
출처 : https://financedata.notion.site/8c858b09203e4404a3b0d1de426dc078